Temporal relational reasoning, the ability to link meaningful transformations of objects or entities over
time, is a fundamental property of intelligent species. We introduce an effective and interpretable network
module, the Temporal Relation Network (TRN), designed to learn and reason about temporal dependencies
between video frames at multiple time scales. We evaluate TRN-equipped networks on activity recognition
tasks using three recent video datasets -
Something-Something, Jester, and Charades - which fundamentally depend on temporal relational reasoning.
Our results demonstrate that the proposed TRN gives convolutional neural networks a remarkable capacity to
discover temporal relations in videos. Through only sparsely sampled video frames, TRN-equipped networks
can accurately predict human-object interactions in the Something-Something dataset and identify various
human gestures on the Jester dataset with very competitive performance. TRN-equipped networks also
outperform two-stream networks and 3D convolution networks in recognizing daily activities in the Charades
dataset. Further analyses show that the models learn intuitive and interpretable visual common sense
knowledge in videos.
Demo Video
Activity recognition for a long video performed by Bolei playing his hands. Model is trained on
something-something dataset created by TwentyBN.
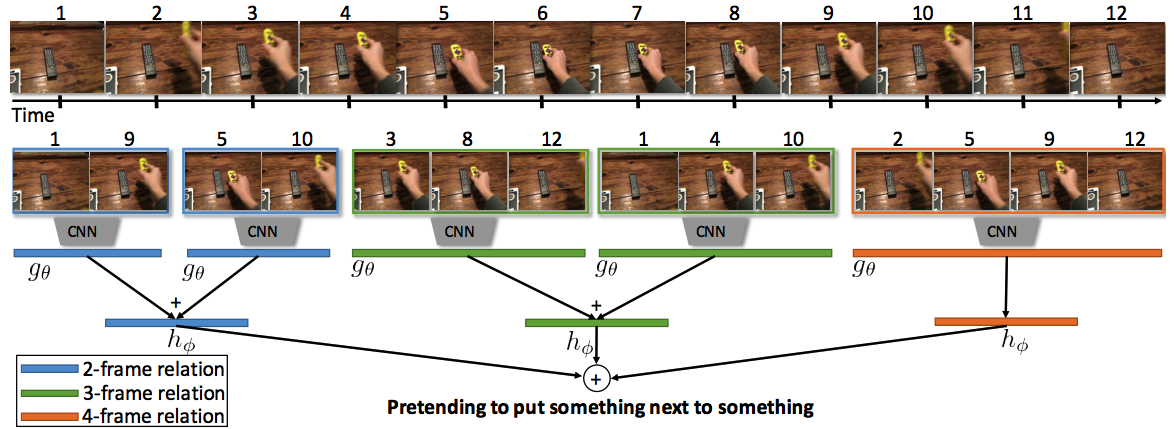
The framework of the temporal relation networks is as follows: To capture the multi-scale temporal relations
inside a video, representative frames of the video are sampled and fed into different frame relation
modules. Please refer to the paper
for the detail.
Reference
B. Zhou, A. Andonian, A. Oliva, and A. Torralba. Temporal Relational Reasoning in Videos. European
Conference on Computer Vision (ECCV), 2018.
[Download Paper]
@article{zhou2017temporalrelation,
title={Temporal Relational Reasoning in Videos},
author={Zhou, Bolei and Andonian, Alex and Oliva, Aude and Torralba, Antonio},
journal={European Conference on Computer Vision},
year={2018}
}
Acknowledgement: Project is supported by the Intelligence Advanced Research Projects
Activity (IARPA) via Department of Interior/ Interior Business Center (DOI/IBC) contract number D17PC00344 and D17PC00341.
The U.S. Government is authorized to reproduce and distribute reprints for Governmental purposes
notwithstanding any copyright annotation thereon. BZ is supported by Facebook Fellowship.
Disclaimer: The views and conclusions contained herein are those of the authors and should
not be interpreted as necessarily representing the official policies or endorsements, either expressed or
implied, of IARPA, DOI/IBC, or the U.S.
Press Coverage
VentureBeat: MIT CSAIL designs AI that can track objects over time.
MIT News: Helping computers fill in the gaps between video frames.